요 며칠은 눈에 띄는 새 결과를 내기보다, 이미 쌓여 있는 실험들을 하나의 파이프라인으로 묶는 작업을 하고 있다. 두 케이스를 같은 논문 안에서 비교하려면, 코드도 같은 구조로 움직여야 한다. 지금 상태처럼 케이스별로 파일이 흩어져 있으면 다시 돌릴 때마다 불안하다.
이번에 정리한 기본 흐름은 아래 여섯 단계다.
| 스텝 | 역할 | 산출물 |
|---|---|---|
| 01 | 수입 데이터 전처리 | import_processed.csv |
| 02 | TRS 집계 변환 | trs_processed.csv |
| 03 | 특징 병합 | merged.csv |
| 04 | 예측 모델 실행 | forecast.csv, eval.csv |
| 05 | 평가 시각화 | data_insight.png, result_insight.png |
| 06 | 조기경보 시뮬레이션 | early_warning/*.png, report.md |
지금은 반도체와 요소수 둘 다 같은 엔트리포인트에서 돌릴 수 있게 만드는 중이다. 데이터셋 이름만 바꾸면 같은 흐름을 타도록 맞추는 것이 목표다. 논문 후반부에 이 작업을 하는 이유는 단순하다. 결과가 많아질수록 재현성이 더 중요해지기 때문이다.
이번에 통합 파이프라인으로 다시 그린 반도체 데이터 탐색 그림은 이런 느낌이다.
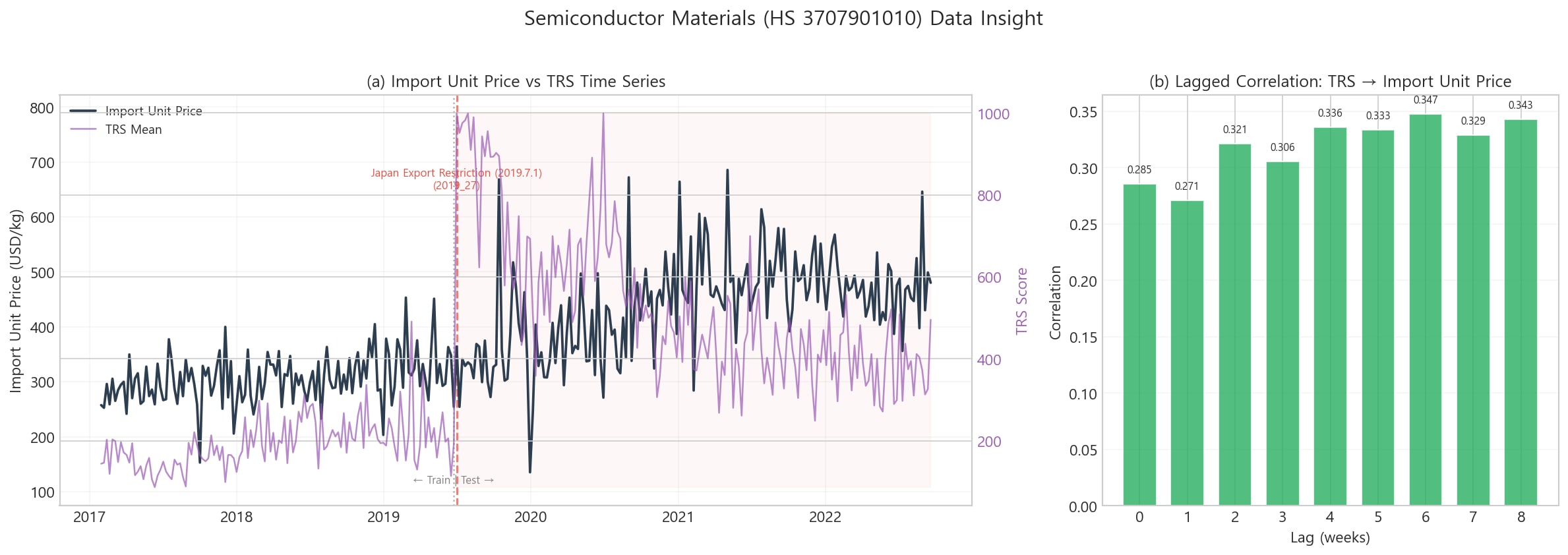
이런 그림이 바로 나오도록 파이프라인을 정리해두면, 나중에 수치를 바꾸거나 그림을 교체할 때 훨씬 덜 흔들린다. 논문을 쓰는 입장에서는 성능을 조금 더 올리는 것만큼이나 중요한 일이다.
지금 느끼는 점
연구 코드는 종종 “돌아가기만 하면 된다”는 식으로 쌓인다. 나도 그렇게 쌓아온 부분이 많다. 그런데 두 케이스 비교, 여러 모델, 조기경보까지 한 문서 안에 같이 들어가기 시작하니, 이제는 돌아가는 것만으로는 부족하다. 다시 돌릴 수 있어야 하고, 단계별 산출물이 명확해야 한다.
솔직히 이런 정리는 재미있는 작업은 아니다. 그래도 지금 하지 않으면 논문 막판에 더 힘들어진다. 이번 주는 결과를 만드는 주간이라기보다, 결과를 믿을 수 있게 만드는 주간에 가깝다.