이번 달에는 한 번 잘 나온 결과를 붙잡고 있기보다, 그 결과가 여러 구간에서도 비슷하게 나오는지 확인하는 데 시간을 많이 썼다. train-test를 한 번 자르는 방식은 설명하기는 쉽지만, 시계열 논문에서는 늘 찜찜함이 남는다. 구간이 바뀌면 결과도 같이 바뀌기 때문이다.
그래서 슬라이딩 윈도우 방식으로 전체 기간을 여러 조각으로 나눠 다시 돌렸다. 피팅 구간과 예측 구간을 순차적으로 옮기면서, LLM 외생변수가 특정 구간의 우연이 아니라 반복 가능한 개선인지 보고 싶었다.
아래 그림은 지금까지 돌린 요약 결과다.
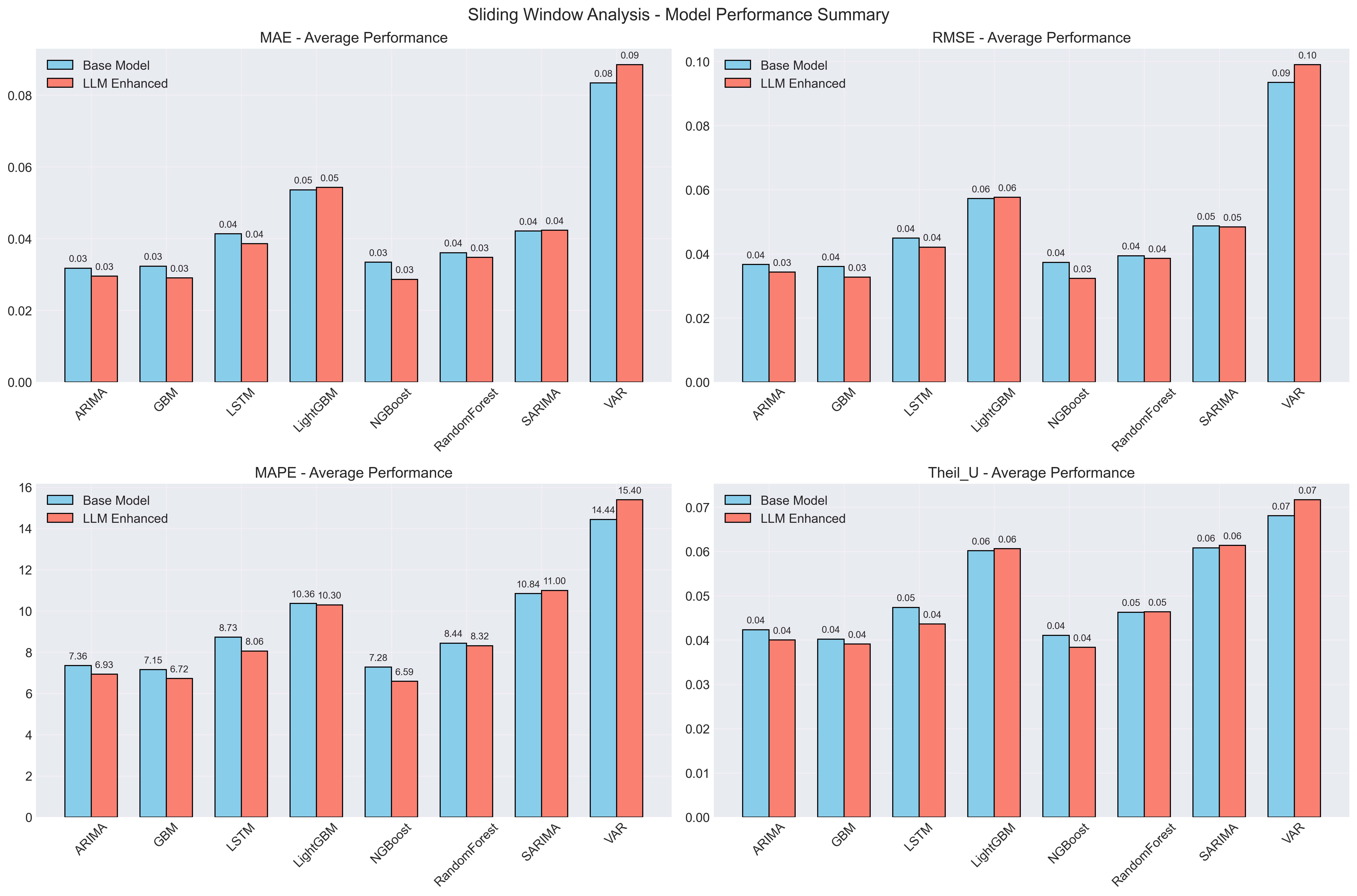
이번에 정리한 상위권 결과는 이렇다.
| 순위 | 모델 | MAE 개선률 | 메모 |
|---|---|---|---|
| 1 | NGBoost | -14.29% | 가장 안정적으로 개선됨 |
| 2 | GBM | -10.12% | 평균 성능과 안정성이 좋음 |
| 3 | ARIMA | -7.02% | 전통 모델에서도 효과 확인 |
| 4 | LSTM | -6.65% | 딥러닝 쪽도 완전히 무시할 정도는 아님 |
| 5 | RandomForest | -3.67% | 보수적이지만 꾸준함 |
이 표가 재밌는 이유는 최고 성능 하나보다, 여러 윈도우를 평균했을 때도 개선 방향이 유지된다는 점이다. 그동안은 특정 충격 구간에서 잘 맞는 그림을 자꾸 보게 됐는데, 이제는 적어도 “구간빨”만은 아니라는 근거가 조금 생긴 느낌이다.
이번 랩미팅에서 받은 피드백도 정확히 그 지점을 찔렀다. 교수님은 단가만 예측하는 게 충분한지, 수량도 같이 봐야 하는 것 아닌지 물으셨다. 또 확률 예측을 활용하면 더 재미있는 결과가 나올 수 있다고 하셨다. 듣고 보니 맞는 말이다. 지금 구조는 평균적인 오차를 보는 데 강하지만, 실제 조기경보로 이어가려면 분포와 확률의 이야기도 필요하다.
지금 보이는 것
슬라이딩 윈도우로 보니 어떤 모델은 특정 구간에서만 좋아 보였고, 어떤 모델은 평균적으로 조금 덜 화려해도 계속 버텼다. 논문에 남길 건 당연히 후자다. 이번 실험은 “가장 좋은 모델”을 고르는 일이라기보다, 어떤 모델이 외생변수를 안정적으로 받아들이는지 보는 일에 가깝다.
다음 작업
이제는 수량 변수도 같이 볼지, 그리고 확률 예측까지 가져갈지를 고민하고 있다. 모델을 하나 더 붙이는 것보다, 지금 얻은 구조를 실무적인 질문으로 연결하는 쪽이 더 중요해 보인다.